As I described in my previous post Getting to Know Distant Reading Techniques , since last summer I have been working in a project concerned about the narratives of the life and experiences of a very popular Afro Argentinian man from the beginning of twentieth century, known as El Negro Raul. Last summer of 2016 I worked with text mining techniques, and although I was planning to use Python for that purposes, I only tested Voyant, since I spent the first two months of the summer preparing the data (transcribing, cleaning and revising the texts). As Megan Brett explains in Topic Modeling: A Basic Introduction:
“Topic modeling is a form of text mining, a way of identifying patterns in a corpus. You take your corpus and run it through a tool which groups words across the corpus into ‘topics’.”
Similarly, in Topic Modeling and Digital Humanities writes:
“Topic modeling provides a suite of algorithms to discover hidden thematic structure in large collections of texts. The results of topic modeling algorithms can be used to summarize, visualize, explore, and theorize about a corpus.”
What could topic modeling add to my current explorations? Would be useful to explore this technique in deeper? An aspect that is repeated by most of the authors we read for this class about topic modeling, is that it works better for large collection of texts, rather than with a small corpus. This make sense, as if you have a small collection you are mostly able to analogically identify the different topics that may be present in these texts. As Ted Underwood’s Topic Modeling Made Just Simple Enough article explains:
“In principle, it could work at any scale, but I tend to think human beings are already pretty good at inferring the latent structure in (say) a single writer’s oeuvre. I suspect this technique becomes more useful as we move toward a scale that is too large to fit into human memory.”
So far, I don’t have a large corpus, but just to see what happens and to think on considering it for future explorations when more texts are added to the collection, I am going to experiment with a set of cartoons about El Negro Raul that appeared during the year of 1916 in the magazine El Hogar. I am interested in seeing the different topic models that are generated, and comparing it to my current speculations after doing a reading of these texts while preparing the data (note: the same as for text mining, you need to convert your files into OCR). I will use Mallet to topic model my sources.
MALLET step by step
I followed The Programming Historian tutorial on MALLET, which helped me a lot for the entire process of installing MALLET. MALLET runs in your command line, and the codes are different for Windows and Mac users so it definitely assisted me in the step by step of getting familiarized with the commands. As previously said, I wanted to first try with a small set of texts, just to see what I got and consider its applicability to larger collections. I followed the instructions from the tutorial (first trying with the sample data that comes with Mallet and then using my own data) and it worked! My only trouble was with the stop words list since I am using Spanish language and not English, and MALLET’s default stop words list is the English one. Once I realized how to do change the stop words list that is used I had no other trouble in creating the topics. I have to say that although using a small amount of texts the outcomes were super interesting, and they definitely supported some initial speculations while they also opened the space for new approaches. Let me talk a bit about them in the next section.
Outcomes
The command I used asked MALLET to find 20 topics and to output a set of files:
- a compressed file that contains every word in my corpus of materials and the topic it belongs to.
- a text document tat shows the top key words for each topic
- a text file that indicates the breakdown, by percentage, of each topic within each original text file that I imported.
To have a better view of this last file I converted it into a spreadsheet:
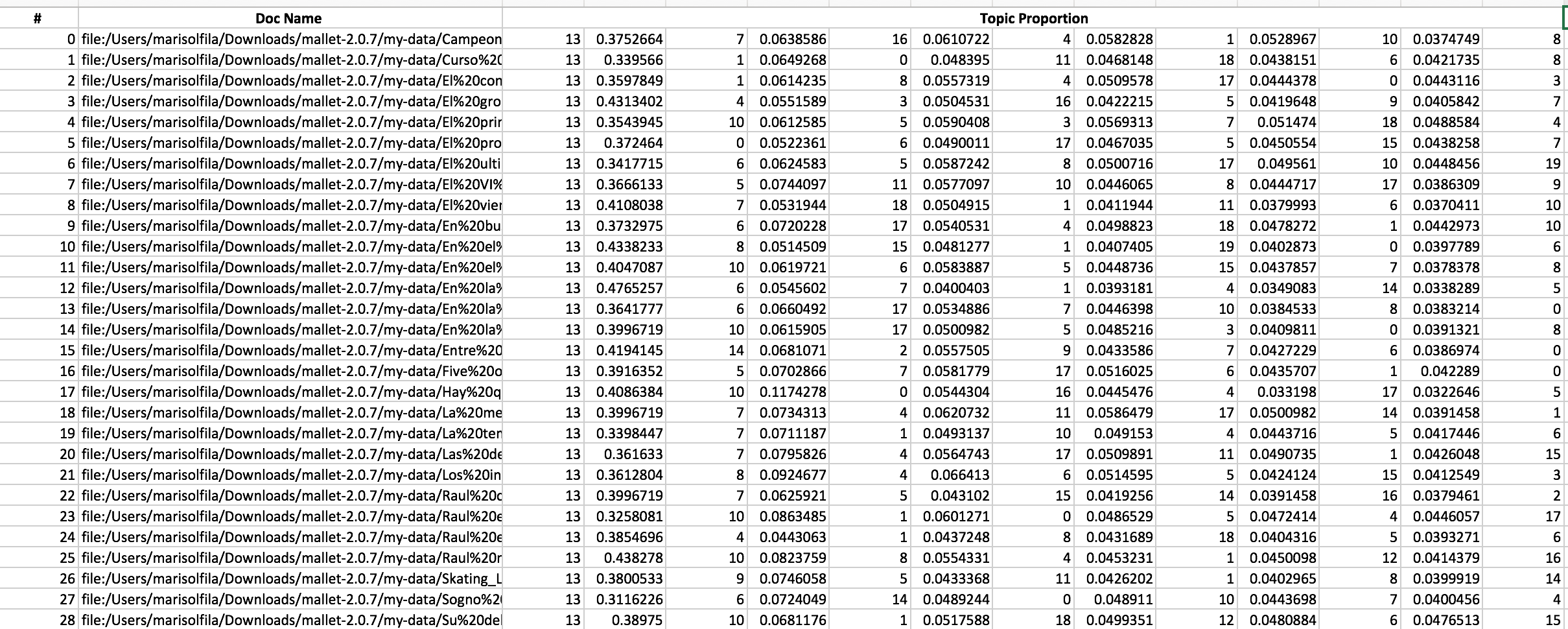
The interesting finding, is that the 13th Topic is the principal topic in each of the documents. But what is the topic 13? I have to take a look at the second file to figure it out:

The topic 13 includes words such as Rau, No, Negro [Black], Moraleja [Moral], Calle [Street], Lector [Reader], Piensa [Think], Gente [People], Mal [Bad], among others. And this is super interesting, for many reasons:
- My previous text mining analysis showed the same words as the most frequent one.
- These cartoons appeared in a magazine to which its audience was the emerging “middle class” and one of the purposes of the magazine was instructing the society how to properly behave. In this sense, Raul’s action were by no means the right model to follow (he was a supposedly out of nowhere black man that wanted to emulate the way of life of the elite but that actually behaved as their clown). Words like no, moral, think, reader and bad are strongly connected to this idea.
- Argentinian’s society was changing during the first decades of the twentieth century and the people was able to move among different and new spaces, specially for free time activities. In this sense, street word makes total sense to appear as one of the principal ones, too.
Moving Forward
Having done this initial experimentations gave me a great idea of what topic modeling could do in a larger set of texts, and I think that by that time, the outcomes will be more original and insightful than the ones that I had (they were super accurate but it is true that it was a work that I could do analogically as well). I will try some new topic modeling with beginning of twentieth century Argentinian’s literature to begin a comparison with what was written about Raul.
... Back to top ...